The world of artificial intelligence (AI) is akin to an uncharted territory, full of unseen wonders waiting to be discovered.
Every now and then, a spark of innovation illuminates this dark territory, bringing us closer to the dawn of a new era.
One such spark is the emergence of synthetic training data, a concept brought to light by the ambitious project of Wave’s GAIA-1.
The CEO of Wave, during a reveal, expressed a firm belief that synthetic training data is not only the future of AI, but a key to unlocking its endless potential.
GAIA-1
GAIA-1’s journey began with less than a hundred Nvidia A1 100s, yet it managed to carve a niche for itself by generating synthetic video data, a feat that not many could achieve. The underlying message was clear: with synthetic data, the sky’s the limit.
This notion was further solidified when it was revealed that the behemoth GP4 was also trained on synthetic data, opening up a world of possibilities not just for large corporations but for scrappy outsiders too.
Imagine the synthetic data that Tesla could conjure with the might of 300,000 A1 100s, especially given that it already boasts billions of hours of real-world data. The stage is set for a revolution in AI training, and GAIA-1 is one of the pioneers leading the charge.
The Magic of Synthetic Data
The synthetic data journey doesn’t just stop at video generation. Just a few days ago, a collaborative effort from UC Berkeley, Google DeepMind, MIT, and the University of Alberta gave birth to UNIS, a simulation capable of replicating real-world scenarios. From unveiling toothpaste to planning out a series of actions for a robot, the power of synthetic data shone bright.
With synthetic data, we’re no longer confined to the shackles of limited real-world data. The constraints that once held back humanoid robotics seem to be fading away, as demonstrated by the Tesla bot, Optimus. It’s a testament to what’s achievable when synthetic data is harnessed to its full potential.
Seeing Through The Lens of AI
As we venture deeper into the realm of synthetic data, another marvel that catches the eye is GPT Vision. By amalgamating the prowess of GPT models with the finesse of visual understanding, GPT Vision stands as a beacon of what’s to come. When compared to its contemporaries, Bard and LLaVA, GPT Vision sets itself apart with its unique approach to bridging the gap between textual and visual understanding.
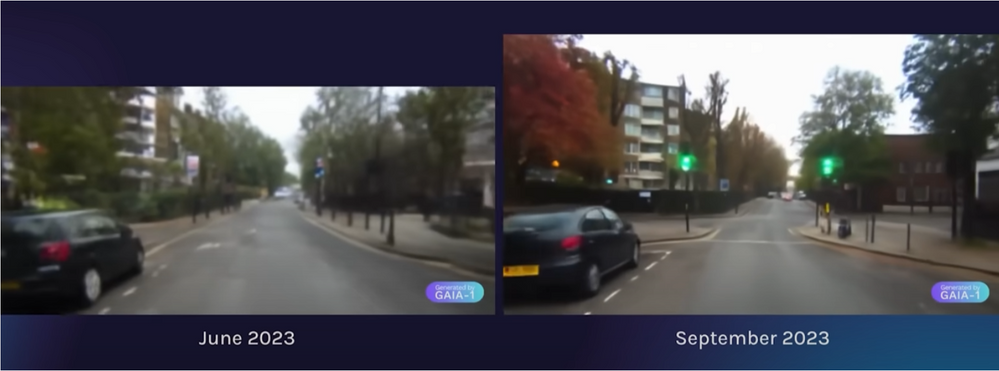
Unveiled in June 2023, GAIA-1 represents the first attempt to embody a generative model that caters to autonomous driving needs. The journey of tuning GAIA-1 has been about enhancing its capability to generate high-resolution videos and elevating the quality of the world model with larger-scale training.

Scaling it up, now GAIA-1 boasts over 9 billion parameters, a gigantic leap from 1 billion parameters in its infancy stage. The training dataset feeding this behemoth comprised 4,700 hours of proprietary driving data collected in London, UK, between 2019 and 2023.
This model isn’t just a show of technical prowess; it’s a utility player in the autonomous driving field. GAIA-1’s ability to generate realistic driving scenarios provides a sandbox for research, simulation, and training endeavors, which are crucial for advancing autonomous driving technology. The fine-grained control it offers over ego-vehicle behavior and scene features makes it a valuable asset for researchers and engineers working in the autonomy space.
The architecture of GAIA-1 is a blend of specialized encoders for each modality (video, text, and action), a core world model, and a video decoder. These encoders transmute the diverse input sources into a shared representation, setting the stage for the world model to predict future image tokens in the sequence.
This prediction is not an isolated process; it’s enriched by the contextual information provided by text and action tokens. The video decoder then translates these image tokens back into the pixel space, ensuring the generated videos are semantically meaningful, visually accurate, and temporally consistent.
Bard vs LLaVA
The Bard and LLaVA, each with their own set of merits, represent the epitome of algorithmic efficiency. The competition between them isn’t just a testament to how far we’ve come, but a glimpse into an exciting future.
These models, each with its unique strengths, contribute to a rapidly evolving AI landscape. They serve as the building blocks for more advanced models, capable of simulating real-world scenarios with an accuracy that was once thought to be unattainable.
Nvidia B100

The engine propelling these advancements is none other than the mighty Nvidia B100. With its unparalleled computational power, the B100 stands as a cornerstone for these evolving technologies. It’s the unsung hero that operates behind the scenes, ensuring the smooth functioning of these sophisticated models.
Why It’s Worth It
Embarking on a journey from GAIA-1 to GPT Vision, from Nvidia B100 to Bard vs LLaVA, isn’t just a leap of faith into the unknown. It’s a calculated stride towards a future where the line between the virtual and real world becomes blurred.
The potential applications of these advancements are boundless. From autonomous driving to real-world robotics, from entertainment to the simulation of long episodes enabling optimization through search planning or reinforcement learning, the impact of these technologies will resonate through various facets of our lives.
The essence of this journey is not just in the sophistication of the technology, but in the promise of a future where AI isn’t just a tool, but a companion in our daily lives. Through the lens of GPT Vision, amidst the clash of Bard and LLaVA, powered by the might of Nvidia B100, we’re not just spectators but active participants in a narrative that shapes the future.
The story of GAIA-1, GPT Vision, Nvidia B100, Bard, and LLaVA is not just a tale of technological advancement, but a narrative filled with hope, promise, and an unyielding spirit of exploration. And as we delve deeper into this narrative, the words of Wave’s CEO echo through the corridors of innovation, reminding us that with synthetic data, we’re on the brink of unlocking an endless realm of possibilities.
Note: The views and opinions expressed by the author, or any people mentioned in this article, are for informational and educational purposes only, and they do not constitute financial, investment, or other advice.
Relevant Articles:
RT-X and the Dawn of Large Multimodal Models: Google Breakthrough
AGI Will Not Be A Chatbot: What Should You Expect
Unleashing AI: The 11 Major Breakthroughs from RT-2 to GPT-4