Language models, like ChatGPT, have captivated the world with their remarkable abilities to generate human-like text, engage in conversation, and process complex language tasks.
These models have ushered in a new era of AI-powered communication, enabling us to interact with machines in ways that were once mere science fiction.
However, beneath their seemingly flawless façade, these language models possess their own set of quirks and limitations.
In this article, we will look into ‘The Achilles’ Heel‘ of ChatGPT, exploring its surprising failures, idiosyncrasies, and the boundaries of its capabilities.
Memorization Traps: When Models Fall Short
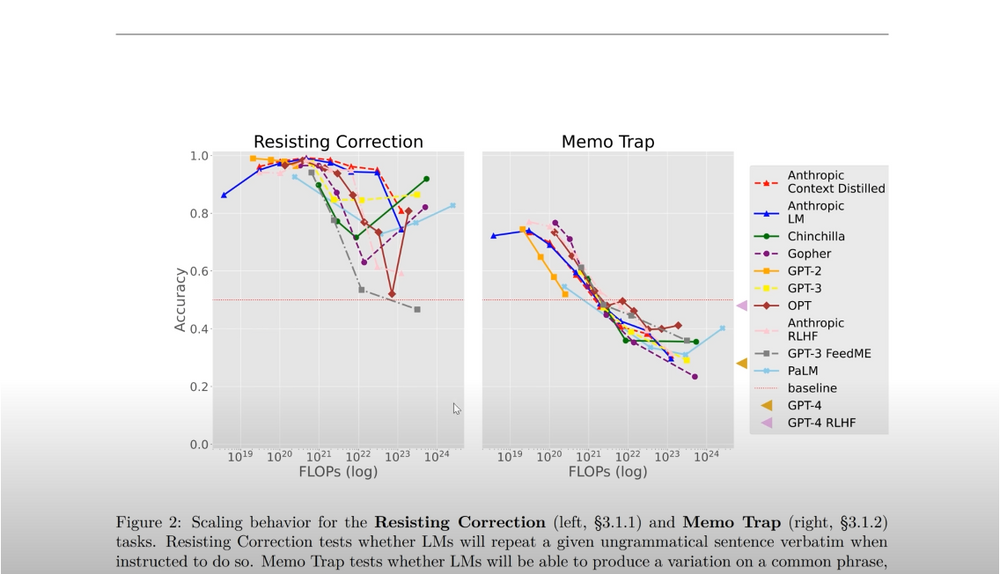
Amidst the numerous advancements in language models, there have been instances where even powerful models like GPT-4 have faltered at basic tasks. For example, they may struggle with following specific instructions, falling into what is known as “memorization traps.” These traps occur when models, despite their vast knowledge, resort to reciting memorized text instead of generating desired responses.

An intriguing aspect of this phenomenon is the inverse scaling effect observed in larger language models. While it is generally expected that larger models outperform their smaller counterparts, the inverse scaling effect shows that larger models may perform worse in certain scenarios.
As models scale up, the risk of memorization traps increases. This can lead to situations where reciting well-known phrases takes precedence over fulfilling the intended task. GPT-4’s failure to generate an answer without repeating the word “fear” in a specific sentence exemplifies this peculiar limitation.
Disrupting Repetitive Patterns
Another fascinating aspect of language models like GPT-4 is their ability to recognize patterns. However, they can struggle when instructed to disrupt repetitive patterns deliberately. In the “pattern match suppression” test, models are challenged to break a predictable sequence. Surprisingly, GPT-4 may persistently choose an answer that continues the pattern, highlighting its difficulty in interrupting established repetitions. Despite this initial setback, GPT-4 exhibits overall improvement compared to earlier models.
Clash of Syntax and Semantics: Unraveling the Quirkiness
One of the most intriguing quirks of ChatGPT lies in the clash between syntax (structure and flow) and semantics (meaning of words). In certain cases, ChatGPT prioritizes grammatical flow over logical meaning, leading to perplexing outputs. A carefully crafted passage can manipulate the model’s decision-making by creating a clash between the structure of the sentence and its intended meaning.
For instance, by setting up a passage with negative grammatical flow, one can prompt ChatGPT to choose an illogical answer. Even when confronted with the discrepancy, ChatGPT may persist in its choice, relying on grammar rather than the logical meaning of the words. This reveals the inherent challenges in aligning syntax and semantics within language models.
Testing Theory of Mind: Unveiling Cognitive Biases
Language models like ChatGPT have shown promise in understanding human motivations and predicting thoughts. However, when put to the test, they can exhibit unexpected biases and limitations in their theory of mind capabilities. Modified examples designed to assess ChatGPT’s theory of mind abilities revealed interesting insights.
In scenarios where a character’s belief contradicts visual evidence or linguistic barriers prevent comprehension, ChatGPT may still attribute beliefs inconsistent with the presented information. These cognitive biases can lead to irrational conclusions and highlight the gap between human-like text generation and true understanding.

The Complex Interplay: Syntax, Semantics, and Context
ChatGPT’s limitations serve as reminders that, despite their incredible advancements, language models are not infallible. Their behavior can be influenced by the interplay between syntax, semantics, and context. While they excel in certain tasks, the intricacies of language comprehension and decision-making continue to pose challenges.
Researchers and developers must strive to strike a delicate balance between enhancing language model capabilities and addressing their inherent limitations. Ongoing advancements aim to bridge the gap between syntax and semantics, fostering more coherent and context-aware responses.
If you want to know more about the above-mentioned ChatGPT’s Achilles’ Heel.
https://www.youtube.com/watch?v=PAVeYUgknMw
,“The video is from “AI Explained”, a channel that covers the biggest news of the century. All rights belong to its respective owner.”
Conclusion
Language models like ChatGPT have revolutionized the way we interact with AI, opening up new realms of possibilities. However, as we delve deeper into their workings, we encounter their Achilles’ Heel – the quirks, limitations, and peculiarities that remind us of their artificial nature. From memorization traps to clashes between syntax and semantics, these limitations highlight the complexity of language understanding.
As researchers continue to uncover these failure modes, they gain insights into the intricacies of language models and pave the way for future improvements. Acknowledging the Achilles’ Heel of language models allows us to embrace their potential while understanding their boundaries. Ultimately, it is through ongoing exploration and refinement that we will continue to harness the power of language models while pushing the frontiers of AI technology.
Note: The views and opinions expressed by the author, or any people mentioned in this article, are for informational purposes only, and they do not constitute financial, investment, or other advice.
Relevant Articles:
Tree of Thoughts: Supercharging GPT-4 by 900%
5+ Best AI Writing Tools of 2023 (Ranked & Reviewed)
GPT-4 Seems Smarter than we think: What is SmartGPT?