






Just a few days ago, in the middle of Google’s and Microsoft’s announcements, there was a language model release that could end up being as impactful as GPT4.
The model is Stanford’s Alpaca, this model behaves qualitatively similarly to OpenAI’s Da-Vinci-003 model, but it is smaller, easier, and cheaper to reproduce – close to $600. What makes it so impressive?
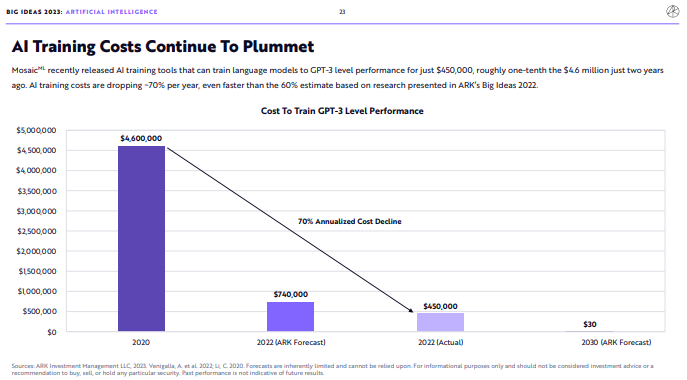
Arc Investment Management put out the below-seen prediction just weeks before the model was released that the 2020 cost of GPT at 4.6 million dollars would take until 2030 to fall to something as insignificant as 30 dollars. If Stanford has done what they claimed, then 99% of this cost reduction has happened within 5 weeks of this prediction being published and not 8 years.

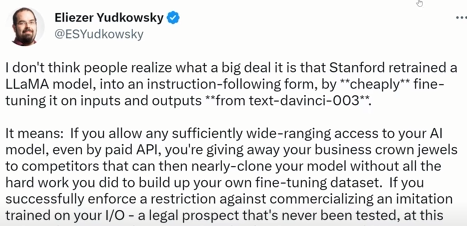
Even the researcher Eliezer Yudkowsky has mentioned in his Twitter account the importance of this event by saying:

Stanford claims that their model performs comparably to the Da-Vinci-003 model, which is GPT 3.5. Seems like this $600 model can compete with ChatGPT!
Let’s dive in and see what Stanford’s Alpaca has in store for us.
What is Alpaca Model?
In recent years, instruction-following language models such as GPT-3.5 and GPT-4 have become increasingly powerful, with many users interacting with them regularly. However, these models still have deficiencies, including:
- The ability to generate false information
- Propagate social stereotypes
- Produce toxic language
To address these problems and promote research in the field, a team of researchers has introduced Alpaca. This instruction-following language model is fine-tuned from the LLaMA 7B model on 52k instruction-following demonstrations.
Alpaca’s training recipe and data have been released, and an interactive demo has been provided to allow the research community to better understand the behavior of the model.
This model is intended solely for academic research, and any commercial use is prohibited. This decision is based on the fact that Alpaca is based on LLaMA, which isn’t use for commercial benefits, and the instruction data used for Alpaca is derived from OpenAI’s text-Davinci-003, which prohibits the development of models that compete with OpenAI according to its terms of use.
But, unfortunately, safety measures have not yet been designed for this model, so it is not ready for general use.
Challenges on Training this Model
Two important challenges must be addressed to be able to train a high-quality instruction-following model under an academic budget:
- A strong pre-trained language model
This first challenge is addressed with the recent release of Meta’s new LLaMA models.
- High-quality instruction-following data
The second challenge, the self-instruct method, is used to generate instruction data.


Alpaca is a language model adjusted finely using supervised learning from LLaMA 7B model on 52K instruction-following demonstrations generated from OpenAI’s text-DaVinci-003. The Alpaca pipeline involves generating instruction-following demonstrations by building upon the self-instruct method. The process involves starting with 175 human written instruction output pairs from the self-instruct seed set and prompting text-DaVinci-003 to generate more guidelines using the seed set as context examples.
The Data generation process results in 52K unique instructions and the corresponding outputs, which cost less than $500 using the OpenAI API.
Equipped with this instruction following dataset, the LLaMA models are fine-tuned using Hugging Face’s training framework, taking advantage of techniques like Fully Sharded Data-Parallel and mixed precision training. Fine-tuning a 7B LLaMA model for the first time took 3 hours using 8 80GB A100s, which costs less than 100 hundred dollars on most cloud computing providers.
DaVinci-003 in Comparison with Alpaca 7B


Alpaca has been evaluated by conducting a human evaluation on the inputs from the self instruct evaluation set. A comparison between text-DaVinci-003 and Alpaca 7B was conducted blindly, in a pairwise manner, and it was found that these two models have similar performance.
This model was found to have much behavior similar to OpenAI’s text-DaVinci-003 but also demonstrates a number of typical inadequacies found in language models, such as hallucination, toxicity, and stereotypes.


Users should watch out as this model has been acknowledged by the research can generate false information. However, the release of this model has enormous benefits for reproducible science, as the academic community can utilize standardized datasets, models, and code to conduct controlled comparisons and explore extensions.
The release of this model is not without risks, according to research that has acknowledged that releasing their training recipe reveals the feasibility of certain capabilities, enabling people to create models that could possibly cause harm. However, they believe that the research community’s benefits outweigh this particular release’s risks.
Conclusion
The release of Alpaca is a significant development in the field of instruction-following language models. Stanford used the weakest of Meta’s LLaMA open-source models (the 7B parameter one), and it was trained by the examples generated using the text-DaVinci-003 model, which cost them about $0.03 per 1000 tokens. Just 48 hours ago, they could have used the GPT-4 model and used 65Billion parameter model and left us speechless. However, most likely, someone is already doing that, so most likely, we will have something similar in the upcoming weeks.
Relevant Articles:
GPT-4 OpenAI release 40% smarter language model with API




