








The AI world is buzzing with excitement!
OpenAI’s ChatGPT, the conversational AI model, is at the center of it all.
With recent developments, there are new ways you can benefit, but there’s also a data controversy that might have significant implications for the future of AI.
Let’s dive into the story.
The Change and How You Can Benefit
OpenAI recently announced a change to ChatGPT’s chat history settings, allowing users to disable chat history and model training. But, what’s behind this change, and how can you benefit?
The answer lies in data privacy. By default, ChatGPT collects and uses user data for training and improving its models.
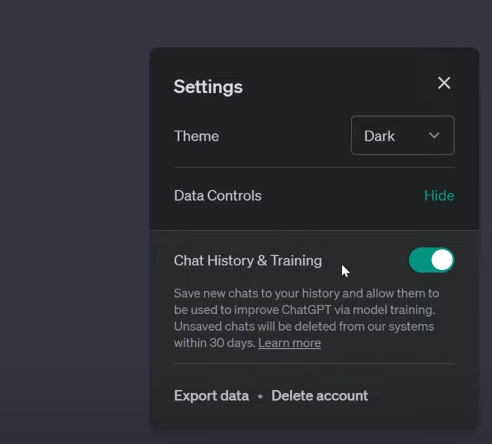
However, now you have the power to opt-out. Did you know that you can turn off chat history in ChatGPT? Meaning your new conversations won’t be used for training. This provides greater control over your privacy.
You have to click on the three dots on the bottom left corner of ChatGPT, then click on ‘Settings‘ and click on ‘Data Controls‘ show.

But, there’s a catch. If you disable chat history, you won’t be able to keep a record of your chats. It’s an all-or-nothing deal. However, there’s a silver lining the new “Export Data” button.
You can now download a complete data export of your conversations, allowing you to review and search through your chat history at your leisure.

The Data Controversy
While these changes sound simple, they’re part of a larger data controversy that could impact OpenAI, the future of GPT-5, and the new information economy.
The problem lies in how AI companies, including OpenAI, collect and use data. For instance, OpenAI has been using Reddit posts, Wikipedia articles, and Stack Overflow content for training its models. But are the creators of this content being compensated? That’s the million-dollar question.
As it turns out, the likes of Reddit and Stack Overflow are looking to charge AI companies for using their data. Legal battles are brewing, with Microsoft and GitHub facing a lawsuit for scraping licensed code to build GitHub’s AI-powered co-pilot tool. Twitter’s CEO even accused OpenAI of illegally using Twitter data.


The GDPR and Global Implications
The data controversy doesn’t end there. OpenAI is facing pressure to comply with the EU’s General Data Protection Regulation (GDPR) the world’s strictest data protection regime. If OpenAI fails to comply, it could be banned in the EU and face hefty fines.
The GDPR’s influence extends beyond Europe. Regulators from Brazil to California are keeping a watchful eye on the outcome, and the result could alter how AI companies collect data worldwide.


The Question of Compensation
As the controversy unfolds, a central question emerges:
- Who gets compensated for data used in AI training?
- Should Reddit users, Wikipedia editors, and Stack Overflow contributors receive a share of the profits made by AI companies?
OpenAI’s CEO, Sam Altman, has expressed willingness to pay for high-quality data in certain domains, but it remains unclear who the beneficiaries will be.
Looking into the Future
Despite the challenges, OpenAI continues to innovate. They’re working on “ChatGPT Business,” a new offering that ensures user data won’t be used for training by default.
Moreover, there’s speculation that AI models like GPT-4 might generate synthetic data sets for training future models like GPT-5, reducing dependency on external data.
Final Thoughts
The ChatGPT history change is more than meets the eye. It’s a development that sheds light on data privacy, compensation, and the future of AI. While users can now benefit from enhanced privacy controls and data exports, the road ahead is filled with legal and ethical dilemmas.
As someone who uses ChatGPT and whose data may have contributed to its training, I find myself in awe of the technological advancements, yet equally concerned about data privacy and fairness.
- How should we navigate the fine line between harnessing AI’s power and protecting user rights?
- Who gets to decide who benefits and who doesn’t?
As the narrative unfolds, we witness the rise of new business models, such as ChatGPT Business, that aim to strike a balance between user privacy and model improvement.
But is it enough?
- Should there be industry-wide standards to regulate AI data usage, or should it be left to individual companies to navigate?
The answers to these questions most likely lie in transparency and collaboration. OpenAI and other AI companies may benefit from actively engaging with the user community, seeking feedback, and ensuring that policies are transparent and inclusive. Moreover, forging partnerships with content creators, websites, and data sources could lead to mutually beneficial agreements.
Ultimately, the data controversy surrounding ChatGPT is a microcosm of the broader AI landscape. The emergence of AI chatbots, language models, and automation technologies has the potential to revolutionize industries, boost productivity, and provide unprecedented convenience to users. However, the ethical considerations surrounding data usage, compensation, and privacy cannot be ignored.
Check out this fantastic information provided by non-other than “AI Explained“:
https://www.youtube.com/watch?v=ivexBzomPv4
As AI industry continues to evolve and mature, we must grapple with fundamental questions about the ownership of data, the ethics of AI training, and the equitable distribution of benefits. The path ahead is complex and fraught with challenges, but the potential for innovation, growth, and positive impact is immense.
Whether you’re an AI enthusiast, a ChatGPT user, or a content creator, it’s an exciting time to be part of the AI revolution. As we continue to explore the possibilities and confront the dilemmas, one thing is certain our collective engagement, vigilance, and ethical considerations will shape the years to come for AI and its role in our lives.
As the story of ChatGPT and the data controversy continues to unfold, we eagerly await the next chapter. With each new development, we gain insights into the dynamic interplay between technology, ethics, and society. Whether it’s the ability to disable chat history, the challenge of GDPR compliance, or the question of compensation, each aspect of the
ChatGPT saga serves as a valuable lesson and a reminder of the transformative power of AI.
So, let’s continue the conversation, embrace the opportunities, and strive for a future where AI is both powerful and responsible a future where technology enhances our lives while respecting our rights.
In conclusion, the ChatGPT history change is not just a feature update; it’s a pivotal moment in the AI journey, shedding light on critical questions that will shape the industry for years to come.
Let’s embrace this moment, learn from it, and work together to create a world where AI and humanity thrive in harmony.
What are your thoughts on this mess? Do you feel safe, personally?
Note: The views and opinions expressed by the author, or any people mentioned in this article, are for informational purposes only, and they do not constitute financial, investment, or other advice.
Relevant Articles:
Meet X.AI Elon Musk’s New AI Venture: The Future is Here
GPT-5 Rollout: Gradual Release & Safety Unveiled by Brockman
OpenAI Unexpected $100 Trillion: Sam Altman’s Vision & More





